RAG-Systeme: So bringst du Firmenwissen in KI – ohne Chaos und Halluzinationen


Endlich dein Unternehmenswissen mit KI koppeln.
ChatGPT weiß viel – aber nicht, was in deinem Unternehmen passiert. Keine Details zu internen Prozessen, keine aktuellen Produktdaten, keine firmenspezifischen Richtlinien.
Genau hier beginnt das Problem: Wenn du KI wirklich produktiv einsetzen willst, muss sie auf dein Wissen zugreifen können. Die Lösung heißt Retrieval-Augmented Generation (RAG) – ein Framework, das Large Language Models mit externem, unternehmenseigenem Wissen verbindet.
Klingt kompliziert? Ist es auch.
Aber mit den richtigen Strategien verwandelst du KI von einem allgemeinen KI-Tool in einen echten Business-Assistenten.
RAG (Retrieval-Augmented Generation) ist eine KI-Technik, bei der ein Sprachmodell vor der Antwort relevante Informationen aus externen Datenquellen abruft.
So entstehen präzisere, aktuellere und nachvollziehbarere Antworten als mit reinem Modellwissen.
Warum reicht ChatGPT allein nicht aus?
Large Language Models wie ChatGPT wurden mit öffentlich zugänglichen Daten trainiert. Sie kennen die Welt da draußen – Wikipedia, Bücher, Webseiten. Aber was steht in deinem CRM-System, welche internen Prozesse gelten und welche Rezepte testet deine Produktentwicklung gerade? Fehlanzeige.
Die naheliegende Idee: Packen wir das Firmenwissen einfach in den Prompt! Theoretisch möglich, denn Kontextfenster von LLMs werden immer größer. Praktisch? Teuer, langsam und fehleranfällig. Je mehr Text du reinwirfst, desto schwerer tut sich das Modell, die wirklich relevanten Infos herauszufiltern – das klassische „Nadel-im-Heuhaufen"-Problem. Die Kunst liegt darin, dem Modell genau so viel Kontext zu geben, wie es braucht. Nicht mehr, nicht weniger.
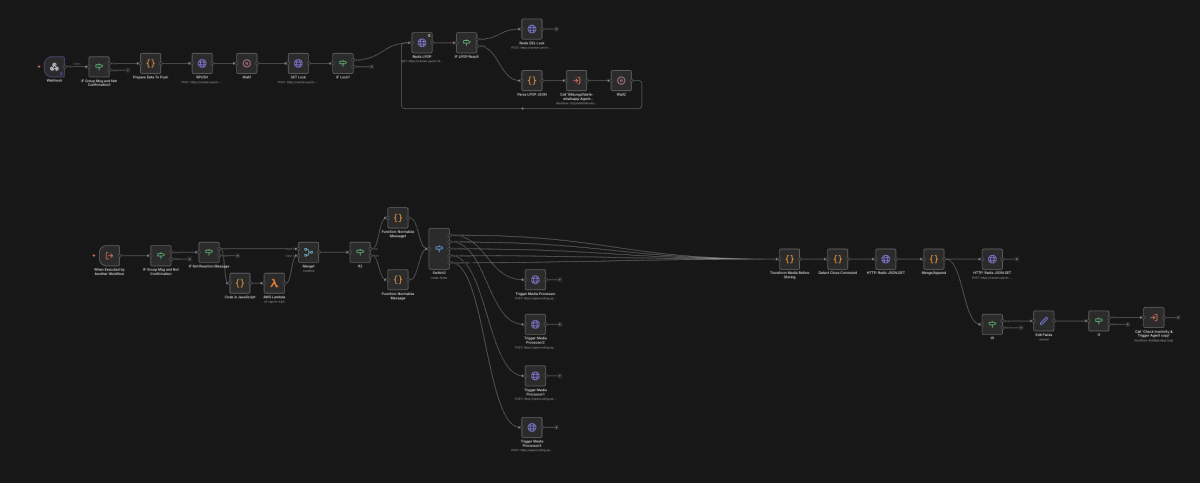
Unser WhatsApp-Agent verarbeitet Kundenanfragen in Echtzeit über einen komplexen Workflow, der Routing, Zustandsmanagement und Medienverarbeitung umfasst. Ohne Retrieval-Augmented Generation (RAG) hätte das zugrunde liegende Sprachmodell keinen Zugriff auf kundenspezifisches Wissen wie Verträge, Onboarding-Status, Produktversionen oder interne Prozessregeln. RAG ist hier geschäftskritisch: Nur durch gezieltes Retrieval aus CRM-, Wissens- und Prozessdaten kann der Agent präzise, konsistente und belastbare Antworten liefern – statt generischer Aussagen oder riskanter Halluzinationen in einem direkten Kundenkanal.
So funktioniert RAG: Wissen finden, statt alles reinzuwerfen
RAG ist kein Hexenwerk, sondern ein cleveres Zwei-Schritte-System:
- Indexierung (Ingestion): Dein Firmenwissen – egal ob Produktkataloge, Handbücher oder andere wichtige Informationen – wird in eine durchsuchbare Form gebracht. Oft kommen hier Vektordatenbanken ins Spiel, die Texte als mehrdimensionale Vektoren speichern. Ähnliche Inhalte liegen im Vektorraum nah beieinander ("Apfel" und "Banane" sind Nachbarn, "Apfel" und "Auto" nicht).
- Retrieval: Wenn jemand eine Frage stellt, durchsucht das System den Index, extrahiert die relevantesten Informationen und fügt sie gezielt in den Prompt ein. Das LLM generiert dann eine fundierte Antwort – basierend auf deinen Daten, nicht auf irgendwelchen Wikipedia-Einträgen.
Das Herzstück sind Embedding-Modelle, die Texte in Vektoren umwandeln. Welches Modell du wählst, ist entscheidend: Es sollte zu deiner Sprache, deinem Fachbereich und deinem Anwendungsfall passen. Ein schlechtes Embedding-Modell liefert schlechte Suchergebnisse – und damit schlechte Antworten.
Der naive Ansatz – und warum er scheitert
Stell dir vor, du willst ein KI-System bauen, das Mitarbeiterfragen beantwortet. Du lädst deine Wissensdatenbank, zerhackst die Texte in kleine Häppchen (sogenannte Chunks), wandelst sie in Vektoren um und legst sie im Vector Store ab. Kommt eine Anfrage wie "Wie onboarde ich einen neuen Kunden?", sucht das System semantisch passende Chunks, packt sie in den Prompt und lässt das LLM antworten.
Klingt gut – funktioniert auch. Aber nur manchmal. Denn dieser naive Ansatz hat Schwachstellen:
- Garbage in, garbage out: Wenn die Chunks unsauber geschnitten sind, verlierst du Kontext. Plötzlich mischt das System Anweisungen aus anderen Guidelines oder liefert unvollständige Anleitungen.
- Halluzinationen: Findet das System keine passenden Daten, erfindet das LLM gerne mal was. Das klingt überzeugend, ist aber frei erfunden – und in Geschäftsanwendungen inakzeptabel.
- Strukturierte Daten fallen durchs Raster: Eine reine semantische Suche findet nicht automatisch "Onboarding 101" oder "Kunden onboarden". Solche Filter brauchen strukturierte Daten – und die musst du gezielt einbinden.
Die Lösung: Kontext bewahren, Metadaten nutzen, intelligent filtern
Wie machst du es besser? Indem du bei der Indexierung Kontext bewahrst und beim Retrieval intelligent filterst.
Metadaten sind Gold wert
Speichere beim Indexieren nicht nur den reinen Text, sondern auch aussagekräftige Metadaten. Zum Beispiel: Prozessname, Zielgruppe (Sales, Customer Success, Enterprise-Kunden), Onboarding-Phase (Pre-Sales, Kickoff, Go-Live), verantwortliches Team, Dauer, Version oder Gültigkeitsdatum. So bleiben fachliche und organisatorische Zusammenhänge erhalten.
Statt das Wissen in viele kleine, zusammenhangslose Textfragmente zu zerlegen, solltest du möglichst sinnvolle Einheiten indexieren – etwa einen vollständigen Onboarding-Prozess oder ein komplettes SOP-Dokument statt einzelner Absätze. Das erhöht die inhaltliche Konsistenz der späteren Antworten deutlich.
Beim Retrieval kombinierst du dann semantische Suche mit Metadaten-Filtern. Das System findet nicht nur inhaltlich passende Informationen, sondern auch genau die, die zu deinem Kontext passen.
Ein Beispiel: Die Anfrage „Wie onboarden wir einen neuen Enterprise-Kunden?“ löst eine Suche aus, die semantisch nach Kunden-Onboarding sucht, aber gleichzeitig über Metadaten filtert:
- Zielgruppe = Enterprise
- Phase = Kickoff / Implementierung
- Version = aktuell
Das Ergebnis ist kein allgemeiner Onboarding-Text, sondern genau der gültige, interne Prozess für Enterprise-Kunden – inklusive der richtigen Schritte, Verantwortlichkeiten und Zeitrahmen.
So wird aus einer generischen KI-Antwort eine präzise, unternehmensspezifische Handlungsempfehlung.
Guardrails gegen Halluzinationen
Damit dein System nicht einfach drauflos fantasiert, brauchst du Guardrails – Sicherheitsmechanismen, die sicherstellen, dass Antworten auf echten Daten basieren. Das kann über System-Prompt-Tuning geschehen ("Antworte nur, wenn du fundierte Infos hast") oder durch nachgelagerte Prüfungen, die checken, ob die Antwort wirklich durch die abgerufenen Daten gedeckt ist.
Agentenbasierte Systeme: Die nächste Evolutionsstufe
Moderne RAG-Systeme entwickeln sich zunehmend zu agentenbasierten Architekturen. Hier entscheidet das LLM autonom, welche Tools es nutzt, wie oft es nachfragt und wie es Informationen kombiniert. Statt starrer Abläufe hast du flexible, adaptive Prozesse.
Ein Beispiel: Dein Agent hat Zugriff auf mehrere Such-Tools – eins für semantische Suche, eins mit Zeitfilter, eins für SQL-Abfragen auf strukturierte Datenbanken. Je nach Anfrage wählt der Agent das passende Tool oder kombiniert mehrere. Das macht das System nicht nur flexibler, sondern auch präziser.
Weitere mögliche Tools:
- Text-zu-SQL-Modelle für direkte Datenbankabfragen
- Hierarchische Suche in Taxonomien oder Kategorien
- KI-gestützte Datenanreicherung, die automatisch wichtige Infos aus Texten extrahiert und als Metadaten speichert

Kundenstimme aus der Praxis: Matthias Bauer, Gründer und Geschäftsführer von Navasto, über die Zusammenarbeit mit APEX und die vollständige Neugestaltung des Marketingprozesses mit messbaren Ergebnissen.
Evaluation: Der blinde Fleck vieler RAG-Projekte
Mit wachsender Komplexität und Autonomie wird ein Thema immer wichtiger: Evaluation. LLMs sind nicht deterministisch – dieselbe Frage führt oft zu unterschiedlichen Antworten. Modelle ändern sich durch Updates. Ohne systematische Qualitätssicherung fliegst du blind.
Menschliche Spot-Checks reichen nicht. Du brauchst automatisierte Evaluationsmethoden. Die gängigste: Ein weiteres LLM fungiert als "Richter" und bewertet automatisch, ob Antworten korrekt, hilfreich oder falsch sind. So generierst du Qualitätsmetriken, die dir zeigen, ob dein System besser wird – oder schlechter.
Der Workflow:
- Erstelle Datensätze mit Testfragen und erwarteten Antworten
- Lass deinen Agenten automatisiert antworten
- Bewerte die Antworten durch einen Evaluation-Layer
- Miss Fortschritte, erkenne Regressionen, optimiere gezielt
Das ist evaluation-driven AI development – das Pendant zur testgetriebenen Entwicklung in der klassischen Softwareentwicklung. Ohne geht's nicht mehr.
Drei Säulen für erfolgreiche RAG-Systeme
Wenn du KI mit Firmenwissen wirklich produktiv machen willst, brauchst du:
1. Eine solide Indexierungs-Pipeline: Daten müssen sorgfältig vorbereitet, transformiert und angereichert werden. Das ist weniger AI-Magie, mehr klassische Datenarbeit (ETL) – aber essenziell.
2. Intelligentes Retrieval: Kombiniere semantische Suche mit Metadatenfilterung, nutze agentenbasierte Architekturen und gib deinem System flexible Tools an die Hand.
3. Systematische Evaluation: Baue Qualitätssicherung von Anfang an ein. Miss, was funktioniert, erkenne Schwachstellen früh und iteriere datengetrieben.
RAG-Systeme sind kein Plug-and-Play. Aber mit der richtigen Herangehensweise verwandelst du KI von einem unpräzisen Ratgeber in einen zuverlässigen, vertrauenswürdigen Business-Partner. Frag uns gerne bei weiteren Fragen – fang innerhalb deines Unternehmens mit einem kleinen Use Case an, indexiere sauber, evaluiere konsequent.
Dein Firmenwissen und deine Mitarbeiter werden es dir danken.
Buche dir heute dein kostenloses Erstgespräch: https://calendly.com/apex-consulting-call/ki-beratung