GPT-5.2 im Praxis-Check: Wann sich das neue Modell wirklich lohnt


Lohnt sich GPT-5.2 für dich oder sind andere Modelle besser?
OpenAI hat mit GPT-5.2 ein Update veröffentlicht, das weniger auf schönere Chatbot-Antworten abzielt – sondern darauf, echte Arbeitsresultate zu liefern. Große Dokumentmengen, mehrstufige Workflows, Excel-Tabellen und Präsentationen: Genau hier soll das neue Modell glänzen. Doch was bedeutet das konkret für dich und dein Team? Und wann ist vielleicht ein anderes Modell die bessere Wahl?
Die drei Gesichter von GPT-5.2
OpenAI liefert GPT-5.2 nicht als Ein-Modell-für-alles aus, sondern als Familie mit drei klaren Profilen:
- Instant: Für schnelle Standardaufgaben, die kostengünstig erledigt werden sollen
- Thinking: Wenn's komplexer wird – mit besserem Reasoning, stärkerer Long-Context-Verarbeitung und Multi-Step-Aufgaben
- Pro: Maximale Qualität und Robustheit für Situationen, in denen Fehler richtig teuer werden
Das klingt erst mal nach Marketing-Sprech. Aber tatsächlich zielt diese Aufteilung auf einen echten Schmerzpunkt: Nicht jede Aufgabe braucht das teuerste Modell – aber für manche ist "gut genug" eben nicht gut genug.
Wo du den Unterschied wirklich spürst
Die Verbesserungen liegen nicht in netteren Formulierungen oder kreativeren Texten. Stattdessen hat OpenAI an drei Stellschrauben gedreht:
Long-Context-Arbeit: Stell dir vor, du hast 200 Seiten Verträge, E-Mail-Threads aus drei Monaten oder technische Spezifikationen vor dir. GPT-5.2 soll genau hier besser werden – nicht nur beim Lesen, sondern beim Synthetisieren und Strukturieren.
Agentische Workflows: Das Modell kann jetzt mehrstufige Abläufe zuverlässiger unterstützen. Zum Beispiel: Dokument klassifizieren → relevante Daten extrahieren → gegen Regeln prüfen → Ergebnis in ein System zurückschreiben. Klingt trocken, ist aber für Automatisierung Gold wert.
Artefakte: OpenAI betont explizit, dass GPT-5.2 bessere Spreadsheets und Präsentationen liefert. Nicht nur Text, sondern arbeitsfähige Outputs, die du direkt weiterverwenden kannst.
Was die Benchmarks wirklich aussagen
OpenAI hat eine Reihe von Benchmarks veröffentlicht, die auf "Wissensarbeit" zielen:
- GDPval (Wissensarbeit): 70,9% (GPT-5.2 Thinking), 74,1% (GPT-5.2 Pro). OpenAI behauptet, hier erstmals "Human Expert Level" erreicht zu haben.
- SWE-Bench Pro (Coding): 55,6% (GPT-5.2 Thinking).
- AIME 2025 (Math): 100% (GPT-5.2 Thinking ohne Tools).
- ARC-AGI-2: 52,9% (GPT-5.2 Thinking), 54,2% (GPT-5.2 Pro).
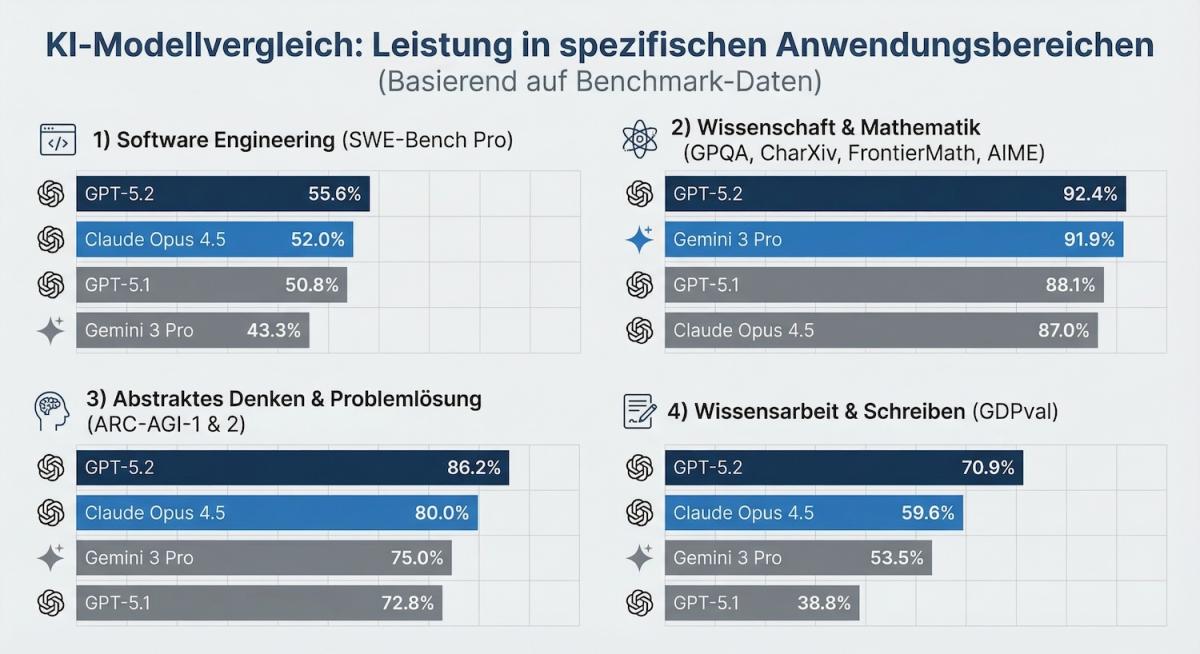
Vergleich führender KI Modelle in vier praxisnahen Disziplinen auf Basis gängiger Benchmarks. GPT 5.2 liegt in allen gezeigten Bereichen vor Claude Opus 4.5, Gemini 3 Pro und GPT 5.1.
Aber Vorsicht: Benchmarks sind keine Garantie für Fehlerfreiheit. Sie zeigen dir die Richtung, nicht die Perfektion. Was sie aber deutlich machen: GPT-5.2 soll nicht nur antworten, sondern Arbeitsresultate produzieren, die sich in deine Prozesse einhängen lassen.
GPT-5.2 vs. Claude vs. Gemini 3 – wer gewinnt?
Die Frage ist falsch gestellt. Es geht nicht darum, wer "der beste Chatbot" ist, sondern: Welches Modell passt zu deiner Art von Arbeit?
Strukturierte Wissensarbeit
Wenn du Reports, Tabellen oder Artefakte brauchst, ist GPT-5.2 sehr stark aufgestellt. OpenAI hat genau darauf den Fokus gelegt. Claude Sonnet und Opus glänzen oft in Textkohärenz und redaktioneller Qualität – je nach Use Case kann das der entscheidende Vorteil sein. Gemini 3 Pro punktet in Enterprise-Workflows, besonders wenn Multimodalität eine Rolle spielt.
Coding und Automations-Engineering
GPT-5.2 positioniert sich mit SWE-Bench Pro als State-of-the-Art. Claude Opus wird als High-End-Modell für anspruchsvolle Aufgaben vermarktet. Gemini 3 Pro ist besonders stark im Google-Ökosystem (Vertex AI).
Long Context
GPT-5.2 kommt mit 400k Kontext und starker Synthese-Fähigkeit. Gemini 3 Pro wirbt mit bis zu 1M Token in Vertex AI – wenn du also extrem viel Kontext brauchst, könnte das relevant sein.
Video-Input
Hier hat GPT-5.2 eine Lücke: Video wird nicht unterstützt. Gemini 3 Pro dagegen schon. Wenn Video-Verarbeitung für dich zentral ist, ist die Entscheidung klar.
Fazit zum Vergleich
- Gemini 3 Pro: Wenn Video, extreme Multimodalität oder 1M Kontext entscheidend sind.
- Claude Opus: Wenn dein Hauptoutput hochwertiger Text ist – Tonalität, redaktionelle Qualität, "Treffsicherheit" im Schreiben.
- GPT-5.2: Wenn du strukturierte Outputs, Long-Context-Arbeit und Multi-Step-Workflows brauchst – und mit wenig prompting gute Ergebnisse willst.
Was GPT-5.2 (noch) nicht perfekt kann
Auch GPT-5.2 bleibt ein probabilistisches System. Drei Dinge solltest du im Hinterkopf behalten:
- Halluzinationen: Reduziert, aber nicht eliminiert. Du brauchst Prüfschritte und Quellenpflicht – besonders in sensiblen Umfeldern.
- Sicherheitsrisiken in vernetzten Setups: Connectoren erhöhen die Produktivität, aber auch die Angriffsfläche (Stichwort: indirekte Prompt-Injection).
- Video-Verarbeitung: Derzeit kein Kernfeature von GPT-5.2.
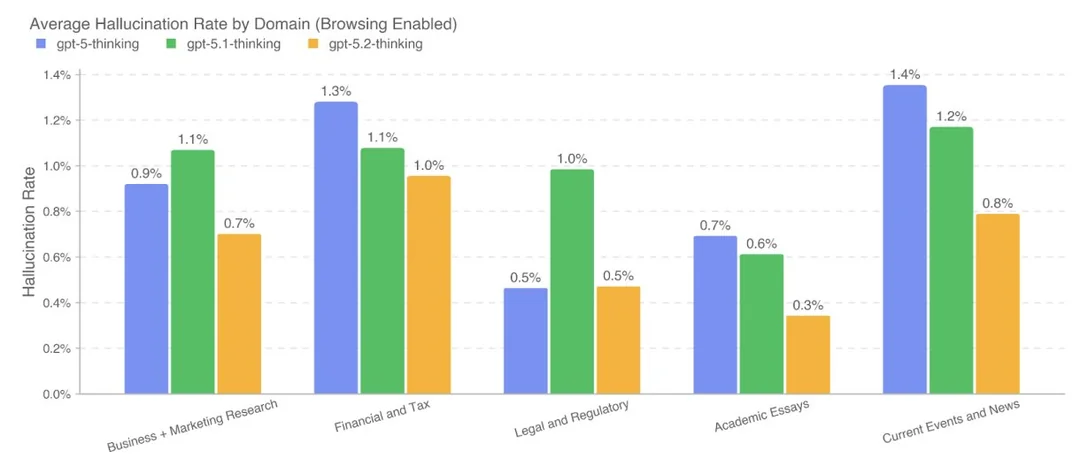
Die Grafik vergleicht die durchschnittliche Halluzinationsrate über verschiedene Domänen hinweg. GPT-5.2 Thinking reduziert Halluzinationen im Vergleich zu GPT-5 Thinking und GPT-5.1 Thinking konsistent.
Prozessautomatisierung: Hier entsteht der größte Hebel
Der wirkliche ROI entsteht nicht, wenn du GPT-5.2 isoliert nutzt – sondern als Baustein in einem System. Hier ein paar typische High-ROI-Workflows, die branchenübergreifend funktionieren:
- Dokumenten-Triage: Eingangskanäle bündeln, klassifizieren, priorisieren, Aufgaben ableiten.
- Extraktion und Strukturierung: Schlüsselwerte, Fristen, Verantwortliche, Risiken, Anlagenlisten, Prüfregeln – alles automatisch erfasst.
- Qualitätsprüfung: Konsistenzchecks, "Missing Info"-Listen, Gegenprüfung gegen interne Standards.
- Reporting: Management-Summaries, KPI-Tabellen, Abweichungsanalysen – fertig zum Versand.
- Wissensdatenbank: Interne SOPs, Richtlinien, Produktdokumentation, Projekthistorien – durchsuchbar und strukturiert.
Genau dafür hat OpenAI die Kombination aus Long Context, Tool-Calling und Artefakten geschärft.
Sensible Daten und Datenschutz: So setzt du GPT-5.2 verantwortungsvoll ein
Wenn du mit sensiblen Daten arbeitest, sind ein paar Punkte nicht verhandelbar.
Training: Was passiert mit deinen API-Daten?
OpenAI dokumentiert, dass API-Daten seit März 2023 nicht zum Training verwendet werden – außer du aktivierst das ausdrücklich. Das ist wichtig, aber nicht das Ende der Datenschutz-Story.
Data Retention: Wie lange werden Inhalte gespeichert?
OpenAI nennt für Plattform- und Abuse-Monitoring standardmäßig bis zu 30 Tage in bestimmten Kontexten, abhängig vom Produkt und der Konfiguration. Für viele Branchen ist das relevant.
Enterprise-Option: Azure OpenAI als Governance-Ansatz
Microsoft dokumentiert für Azure OpenAI, dass Prompts und Completions nicht zum Training der Basismodelle genutzt werden, und betont "stateless" Verarbeitung. Für EU-Unternehmen ist das Thema EU Data Boundary zentral – Microsoft beschreibt den Rahmen zur Datenresidenz innerhalb dieser Boundary.
Praktische Leitplanken (unabhängig vom Anbieter)
Egal, ob du OpenAI direkt, Azure oder einen anderen Anbieter nutzt – diese Grundsätze gelten immer:
- Datenminimierung: Nur das hochladen, was zur Aufgabe nötig ist.
- Pseudonymisierung/Redaktion: Personenbezogene Details wo möglich entfernen.
- Netzwerkisolation: Private Endpoints, Zugriff nur aus dem Firmennetz.
- Audit und Freigabe: Rollen, Logging, Freigaben für kritische Outputs.
- Prompt-Injection-Tests: Besonders wichtig bei vernetzten Dokumentquellen und E-Mail-Workflows.
Dein Takeaway: Wann GPT-5.2 die richtige Wahl ist – und wann nicht
GPT-5.2 ist besonders interessant, wenn du:
- Große Dokumentmengen verarbeiten musst
- Strukturierte Outputs brauchst (Tabellen, Artefakte, Reports)
- Multi-Step-Workflows automatisieren willst
- Das Ganze mit Governance für sensible Daten absichern musst
Andere Modelle können sinnvoller sein, wenn:
- Video oder starke Multimodalität Kernanforderung ist (Gemini 3 Pro)
- Redaktionelle Textarbeit und Tonalität im Vordergrund stehen (Claude Opus/Sonnet)
Probier das heute selbst aus: Nimm eine konkrete Aufgabe aus deinem Alltag – einen Report, eine Dokumentenanalyse, eine Extraktion – und teste GPT-5.2 (Thinking oder Pro) dagegen. Schau, ob die Outputs wirklich arbeitsfähig sind. Und wenn ja: Überlege, welchen nächsten Schritt du automatisieren könntest.